Intuition
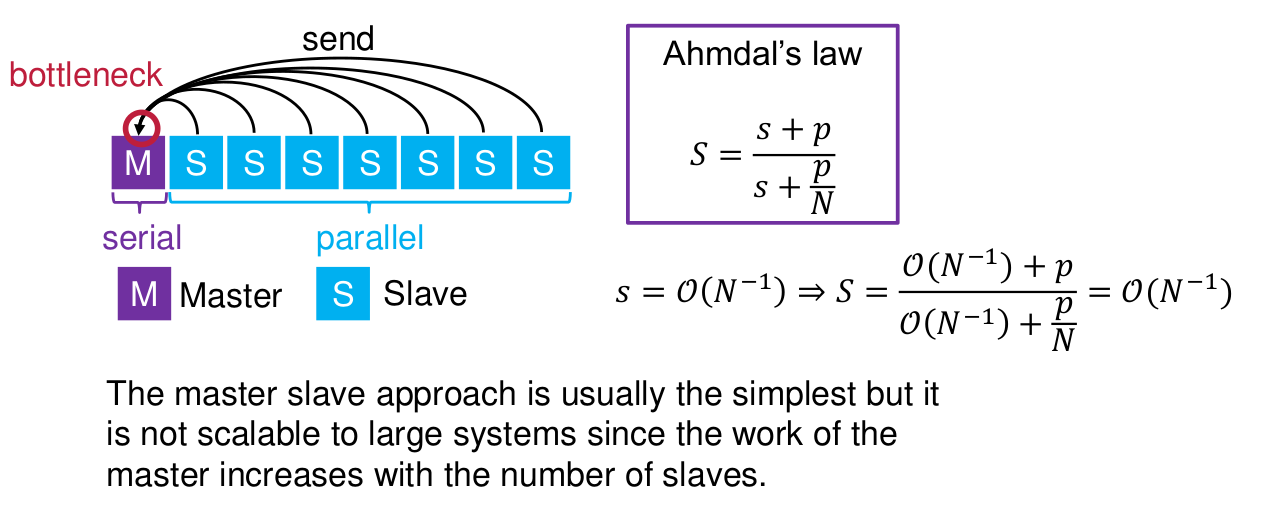
Task 1
The C++ code below calculates the value of π by numerically integrating the function for a quarter circle. The provided version is serial and only works correctly for a single process.
Your task is to parallelize this code using the MPI Master-Slave approach. The master process (rank 0) should be responsible for summing the final result, while all other slave processes should compute their portion of the integral and send it to the master.
#include <iostream>
#include <cmath>
// Forward declarations for the integration functions
double integral(double boundaryLeft, double boundaryRight, long divisions);
double f(double x);
int main(int argc, char **argv)
{
// These variables will need to be set by MPI
int number_of_processes = 1;
int my_rank = 0;
double result = 0.0;
double local_integral = 0.0;
const long number_of_intervals = 5040 * 100000;
const double global_a = 0.0;
const double global_b = 1.0;
// The calculation is done in this loop
const long local_number_of_intervals = number_of_intervals / number_of_processes;
const double local_interval_width = (global_b - global_a) / (double)number_of_processes;
const double local_a = global_a + my_rank * local_interval_width;
const double local_b = local_a + local_interval_width;
local_integral = integral(local_a, local_b, local_number_of_intervals);
// --- Add your MPI communication logic below ---
// --- End of communication logic ---
result += local_integral;
if (my_rank == 0)
{
printf("Result: %0.20f \n", result * 4.);
}
return 0;
}
// Note: You do not need to modify the 'integral' or 'f' functions.
// double integral(...) { ... }
// double f(...) { ... }- Add the necessary MPI include header and initialize the MPI environment at the start of
main(). Set themy_rankandnumber_of_processesvariables correctly. - Inside the designated “communication logic” area, implement the Master-Slave pattern.
- Add the call to finalize the MPI environment before the program returns.
Solution
The solution requires adding the MPI initialization and finalization calls, and implementing the Master-Slave communication logic where the master (rank 0) receives results from all slaves.
#include <iostream>
#include <cmath>
#include <mpi.h> // 1. Include the MPI header
// Forward declarations for the integration functions
double integral(double boundaryLeft, double boundaryRight, long divisions);
double f(double x);
int main(int argc, char **argv)
{
int number_of_processes = 1;
int my_rank = 0;
// 1. Initialize MPI and set rank/size variables
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &number_of_processes);
double result = 0.0;
double local_integral = 0.0;
const long number_of_intervals = 5040 * 100000;
const double global_a = 0.0;
const double global_b = 1.0;
const long local_number_of_intervals = number_of_intervals / number_of_processes;
const double local_interval_width = (global_b - global_a) / (double)number_of_processes;
const double local_a = global_a + my_rank * local_interval_width;
const double local_b = local_a + local_interval_width;
local_integral = integral(local_a, local_b, local_number_of_intervals);
// --- 2. Master-Slave communication logic ---
if (my_rank == 0) {
// Master Process
double receive_buffer = 0.0;
// The master sums its own result implicitly later
result = 0.0;
for (int source_id = 1; source_id < number_of_processes; source_id++)
{
MPI_Recv(&receive_buffer, 1, MPI_DOUBLE, source_id, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
result += receive_buffer;
}
} else {
// Slave Processes
MPI_Send(&local_integral, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
}
// --- End of communication logic ---
// The master adds its own computed part to the final sum
result += local_integral;
if (my_rank == 0)
{
printf("Result: %0.20f \n", result * 4.);
}
// 3. Finalize MPI
MPI_Finalize();
return 0;
}