Bias
In a model, it is the systematic error that is cause due to wrong assumptions made during the learning process.
Variance
It is the measure of the deviation of the data from it’s mean position.
where,
- Predicted target value
- Actual target value
- Dataset
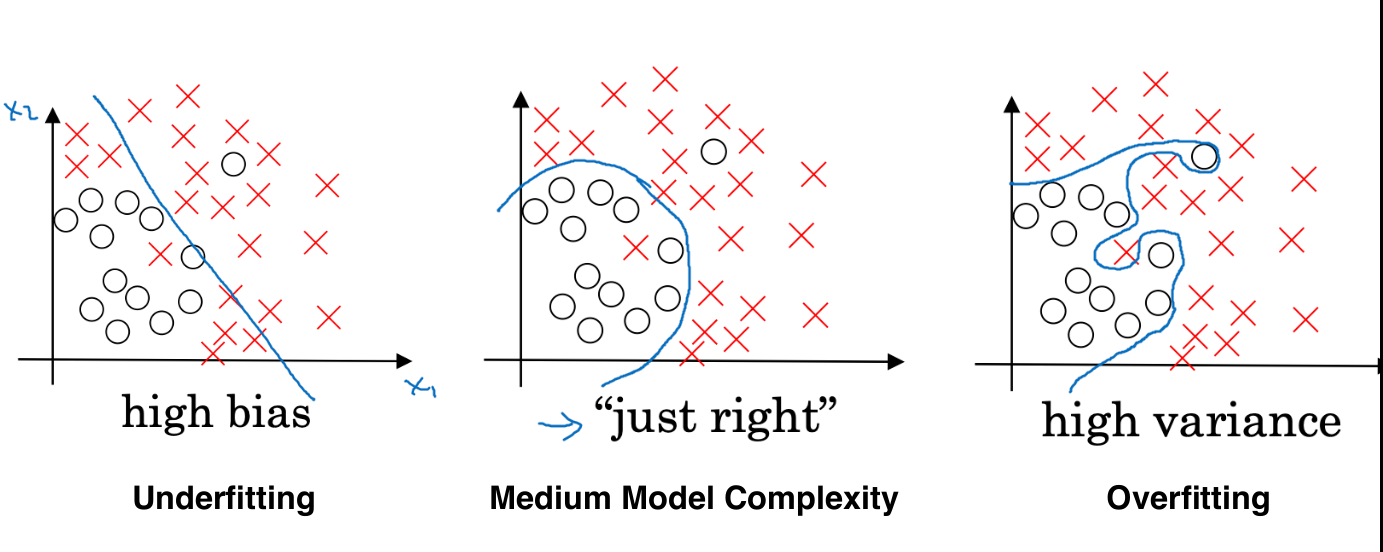
To Reduce HIGH BIAS (Underfitting):
- Increase model complexity
- Add more features
- Reduce regularization (smaller λ)
To Reduce HIGH VARIANCE (Overfitting):
- Reduce model complexity
- More training data
- Regularization (L1/L2)
- Early stopping
- Cross-validation