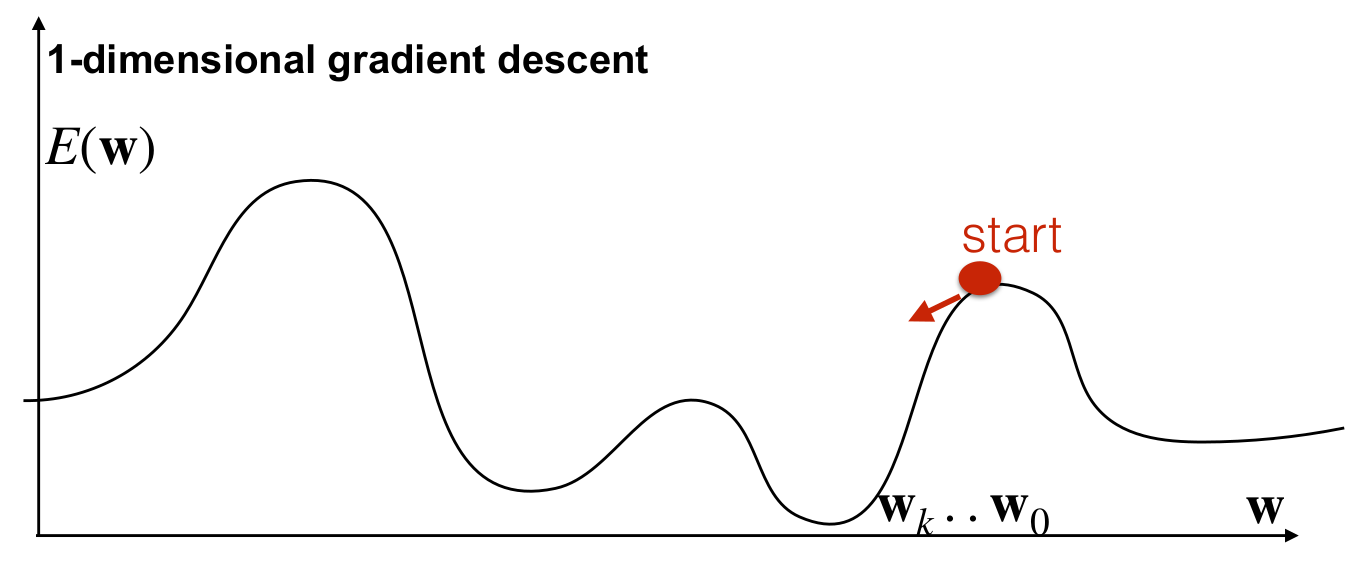
 The learning rule for gradient descent is
The learning rule for gradient descent is
Where:
- is the parameter vector at iteration
- is the updated parameter vector for the next iteration
- is the learning rate (a positive scalar value)
- is the gradient of the error function with respect to parameters
This iterative update rule moves the parameters in the direction of steepest descent of the error function, with the step size controlled by the learning rate . The process continues until the gradient becomes approximately zero () or some other stopping criterion is met.