The k-means algorithm is an iterative method to partition N data points into K clusters. For two clusters, the process is as follows:
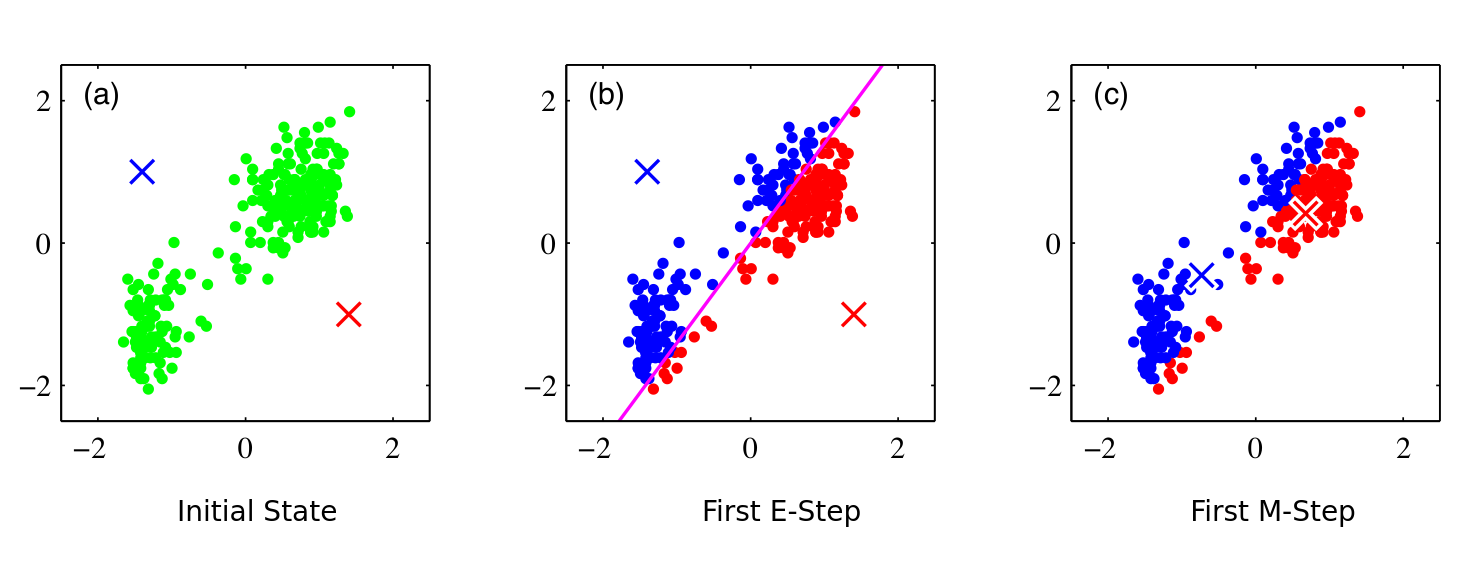
- Initialization: Randomly initialize the positions of two prototypes (cluster centers), let’s call them the red ‘x’ and the blue ‘x’.
- Assignment Step (E-step): Assign each data point to the nearest prototype. All points closer to the red ‘x’ become part of the red cluster, and all points closer to the blue ‘x’ become part of the blue cluster. This partitions the data space.
- Update Step (M-step): Recalculate the position of each prototype by taking the mean (center) of all data points assigned to its cluster. The red ‘x’ moves to the center of the red data points, and the blue ‘x’ moves to the center of the blue data points.
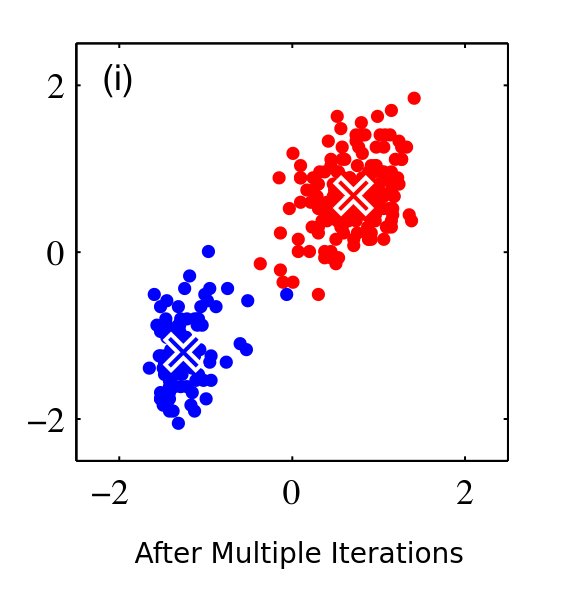
- Repeat: Steps 2 and 3 are repeated until the cluster assignments no longer change, meaning the algorithm has converged to a solution.
Optimization Criteria
K-means minimizes the quantization error, which is the sum of the squared distances between each data point and its assigned cluster’s prototype . The objective function is:
Where is 1 if data point is assigned to cluster , and otherwise.