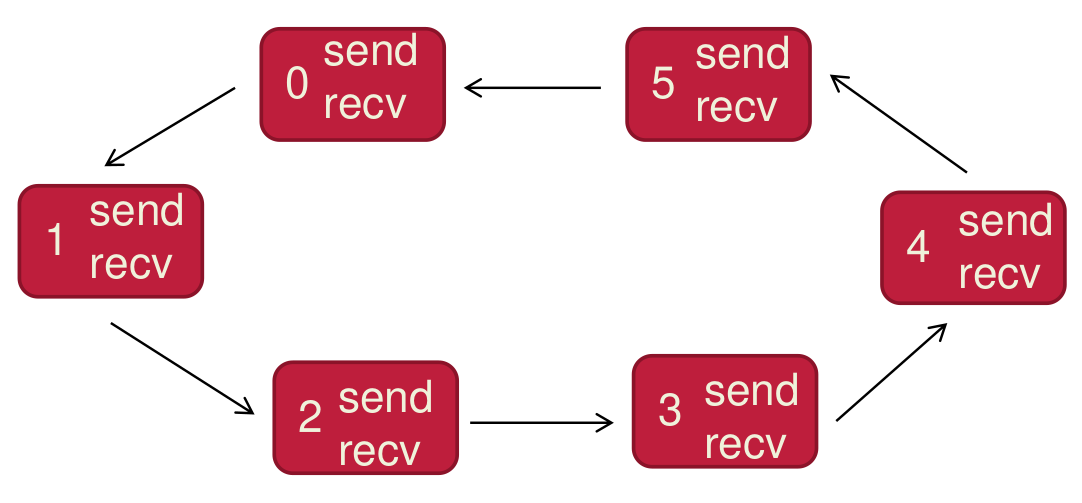
 In Message Passing (MPI): Deadlocks can occur with synchronous communication patterns. For example, in the ring communication pattern shown above, if all processes try to send before receiving (using synchronous sends like
In Message Passing (MPI): Deadlocks can occur with synchronous communication patterns. For example, in the ring communication pattern shown above, if all processes try to send before receiving (using synchronous sends like MPI_Ssend), they will all block waiting for their messages to be received. Since everyone is trying to send and no one is receiving, a deadlock occurs.
Example
The following MPI program is intended to have each process send its rank to its left-hand neighbor and receive a rank from its right-hand neighbor in a ring topology. However, a critical logic error from the original, working code has been introduced, causing the program to hang indefinitely when executed.
#include <iostream>
#include <stdio.h>
#include <mpi.h>
int main (int argc, char **argv){
MPI_Status status;
int my_id, num_procs;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
MPI_Comm_rank(MPI_COMM_WORLD, &my_id);
// Ring topology setup
int destination = my_id - 1;
if (my_id == 0) destination = num_procs - 1;
int source = my_id + 1;
if (source == num_procs) source = 0;
double my_old_data = my_id;
double my_new_data;
MPI_Ssend(&my_old_data, 1, MPI_DOUBLE, destination, 0, MPI_COMM_WORLD);
MPI_Recv(&my_new_data, 1, MPI_DOUBLE, source, 0, MPI_COMM_WORLD, &status);
// The rest of the code gathers results to process 0 for printing.
if (my_id == 0) {
double* a = new double[num_procs];
a[0] = my_new_data;
double temp;
for (int p = 1; p < num_procs; p++) {
MPI_Recv(&temp, 1, MPI_DOUBLE, p, 0, MPI_COMM_WORLD, &status);
a[p] = temp;
}
for (int p = 0; p < num_procs; p++) {
std::cout << "a[" << p << "]=" << a[p] << std::endl;
}
delete[] a;
} else {
MPI_Send(&my_new_data, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
}
MPI_Finalize();
return 0;
}
- Identify and name the specific problem that causes the program to hang.
- Explain precisely why this problem occurs. Why do the
MPI_SsendandMPI_Recvcalls in this specific order lead to a permanent halt? - Rewrite the “Problematic Communication Block” to fix the issue, ensuring the program runs correctly without deadlocking.
Solution
1. Identification of the Problem
The program is experiencing a deadlock.
2. Explanation of the Deadlock
- A synchronous send,
MPI_Ssend, is a blocking operation. It will pause the process until a matchingMPI_Recvhas been posted by the destination process. (handshake) - In the provided flawed code, every single process calls
MPI_Ssendbefore it callsMPI_Recv. - This creates a circular dependency:
- Process 0 is waiting for Process
N-1to callMPI_Recv. - Process 1 is waiting for Process 0 to call
MPI_Recv. - …and so on, until Process
N-1is waiting for ProcessN-2to callMPI_Recv.
- Process 0 is waiting for Process
- Since every process is stuck waiting in
MPI_Ssend, no process can ever move on to callMPI_Recv. This circular wait condition is a classic deadlock.
3. Corrected Code
The deadlock is resolved by breaking the symmetry of the communication pattern. We can do this by having even-ranked processes send then receive, while odd-ranked processes receive then send. This ensures that for every MPI_Ssend, there is a corresponding MPI_Recv ready to accept it.
The corrected communication block should be:
// --- Corrected Communication Block ---
if (my_id % 2 == 0) {
// Even processes send first, then receive
MPI_Ssend(&my_old_data, 1, MPI_DOUBLE, destination, 0, MPI_COMM_WORLD);
MPI_Recv(&my_new_data, 1, MPI_DOUBLE, source, 0, MPI_COMM_WORLD, &status);
} else {
// Odd processes receive first, then send
MPI_Recv(&my_new_data, 1, MPI_DOUBLE, source, 0, MPI_COMM_WORLD, &status);
MPI_Ssend(&my_old_data, 1, MPI_DOUBLE, destination, 0, MPI_COMM_WORLD);
}
// --- End of Block ---